机器学习引言
1.
sklearn与特征工程
1.1.
数据的来源与类型
1.2.
数据的特征抽取
1.3.
数据的特征预处理
1.4.
数据的特征选择
2.
sklearn数据集与机器学习组成
2.1.
Scikit-learn数据集
2.2.
模型的选择
2.3.
模型检验-交叉验证
2.4.
sklearn的estimator
3.
sklearn的分类器算法
3.1.
分类算法之k-近邻
3.2.
k-近邻算法案例分析
3.3.
朴素贝叶斯
3.4.
分类算法之逻辑回归
3.5.
逻辑回归算法案例分析
3.6.
分类器性能评估
3.7.
分类算法之决策树、随机森林
4.
回归算法
4.1.
回归算法之线性回归
4.2.
线性回归案例分析
4.3.
回归性能评估与欠拟合、过拟合
4.4.
回归算法之岭回归
4.5.
岭回归案例分析
5.
非监督学习
5.1.
非监督学习之k-means
5.2.
k-means案例分析
6.
推荐系统
6.1.
推荐系统评测
6.2.
基于协同过滤的推荐系统
6.3.
代码案例
Published with GitBook
机器学习课件
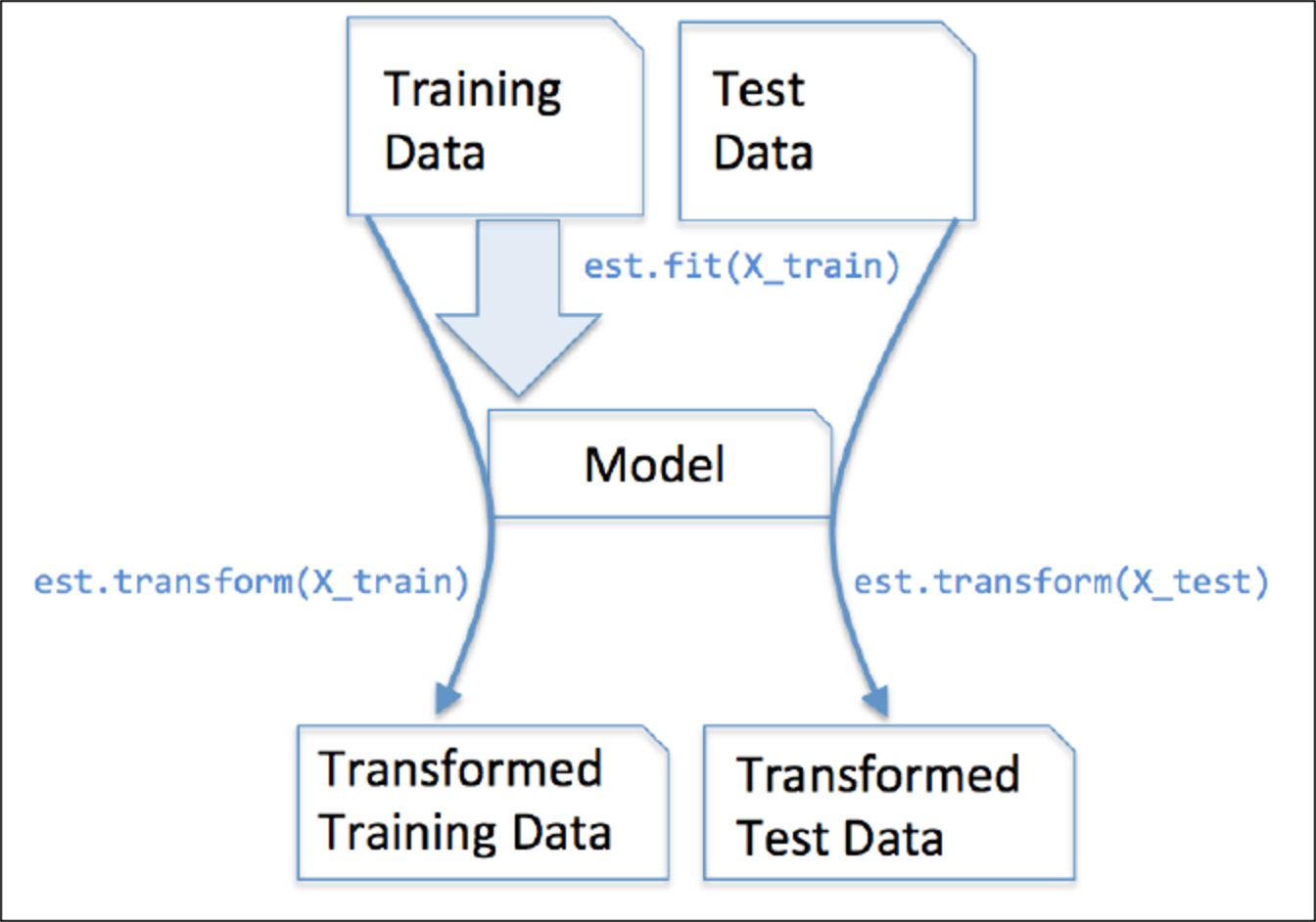
estimator的工作流程
在sklearn中,估计器(estimator)是一个重要的角色,分类器和回归器都属于estimator。在估计器中有有两个重要的方法是fit和transform。
fit方法用于从训练集中学习模型参数
transform用学习到的参数转换数据